Hamdar server metrics
داشبورد Hamdar server metrics
برای آشنایی با روش خواندن پنلها، معماری سامانه و اصطلاحات این راهنما، به راهنمای پنل مانیتورینگ مراجعه کنید. جزئیات هشدارها و اقدامات پیشنهادی نیز در بخش هشدارها آمده است.
کاربرد داشبورد
این داشبورد نمای کلی و تفصیلی از وضعیت سرور همدار ارائه میدهد. با استفاده از آن میتوانید مصرف CPU و حافظه، فضای ذخیرهسازی، ترافیک شبکه و وضعیت فرایندها را بررسی کنید.
بیشتر هشدارهای مرتبط با سرور، مستقیماً به پنل متناظر در این داشبورد لینک شدهاند.
نمای سریع منابع
Quick CPU / Mem / Disk
این ردیف مهمترین شاخصهای سلامت سرور را در یک نگاه نشان میدهد: CPU Busy و Sys Load برای فشار پردازشی، RAM Used و SWAP Used برای فشار حافظه، Root FS Used برای ظرفیت فایلسیستم، Uptime برای تشخیص Restart و Pressure برای زمان انتظار CPU، حافظه و I/O. مصرف پایدار CPU بالاتر از ۸۰٪، RAM یا Root FS بالاتر از ۸۵٪ و Swap بالاتر از ۵۰٪ نیازمند بررسی است.

CPU، حافظه، شبکه و دیسک
Basic CPU / Mem / Net / Disk
این ردیف نمودارهای خلاصه CPU Usage، Memory Basic، Network Traffic Basic و Disk Space Used Basic را برای بررسی سریع روند منابع نمایش میدهد. جهش یا افت غیرعادی را با رویدادهای همان بازه زمانی تطبیق دهید.
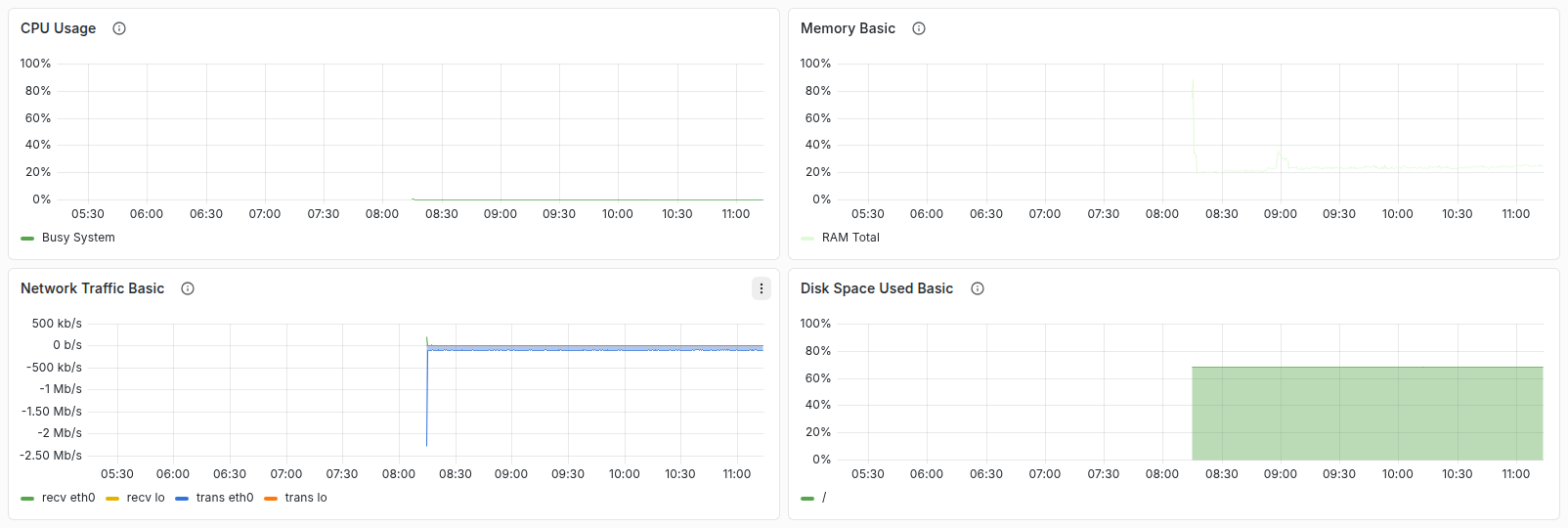
CPU / Memory / Net / Disk
این ردیف جزئیات CPU، توزیع حافظه، ترافیک شبکه، فضای دیسک، IOPS، زمان خواندن و نوشتن و Utilization ذخیرهسازی را نشان میدهد. iowait یا Utilization پایدار بالا میتواند نشانه گلوگاه I/O باشد و رشد حافظه غیرقابلبازیابی میتواند به Leak اشاره کند.
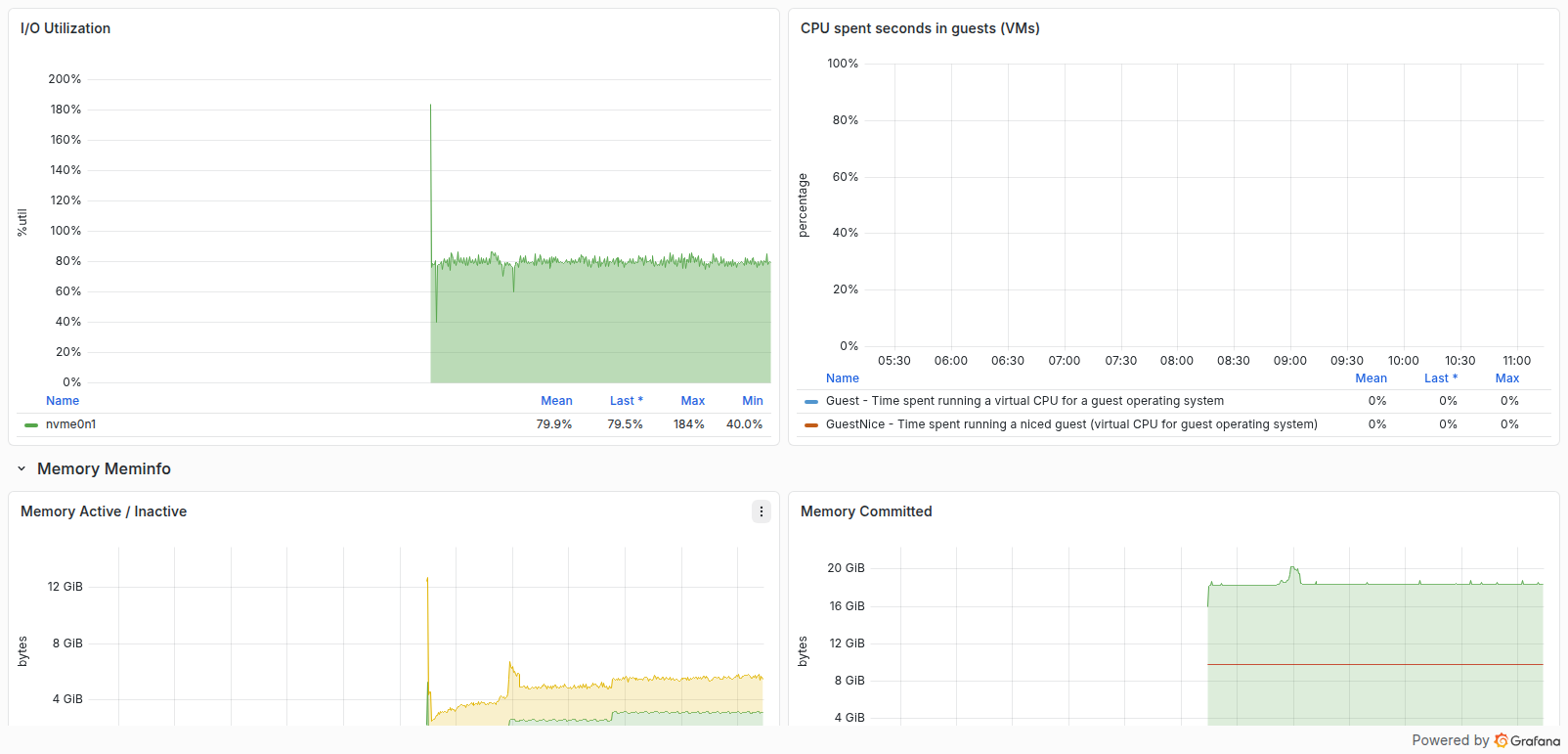
جزئیات حافظه
Memory Meminfo
این ردیف Active و Inactive، Committed، Writeback و Dirty، Slab، Vmalloc، HugePages و DirectMap را نمایش میدهد. رشد پیوسته Slab، Vmalloc یا Committed که پس از کاهش بار به حالت عادی بازنمیگردد میتواند نشانه نشت حافظه در Kernel، Driver یا workload باشد.
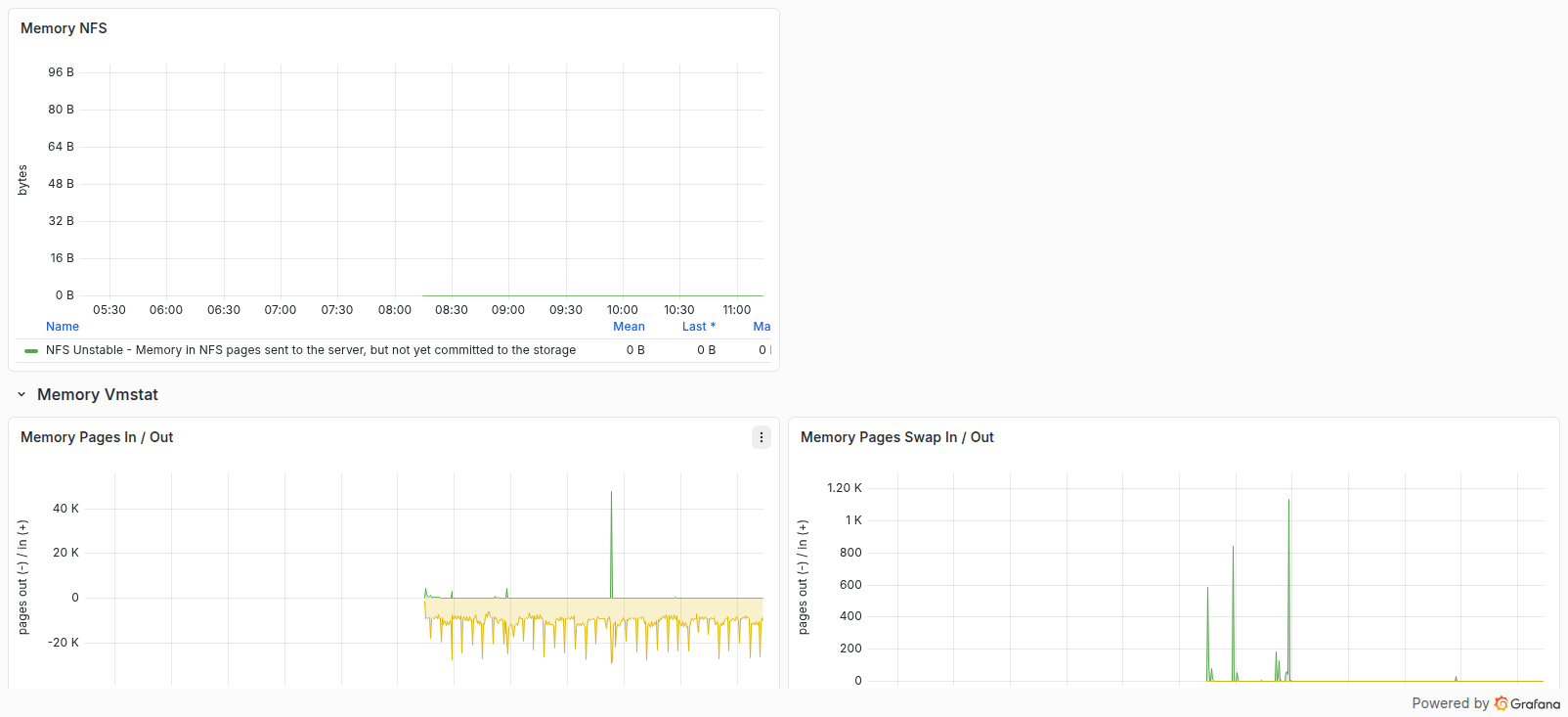
Memory Vmstat
این ردیف Page In/Out، Swap In/Out، Page Fault و OOM Killer را نشان میدهد. هر مقدار مثبت OOM را بلافاصله بررسی کنید؛ افزایش پایدار Major page fault، بهویژه همراه با Swap I/O، میتواند نشانه فشار حافظه باشد.
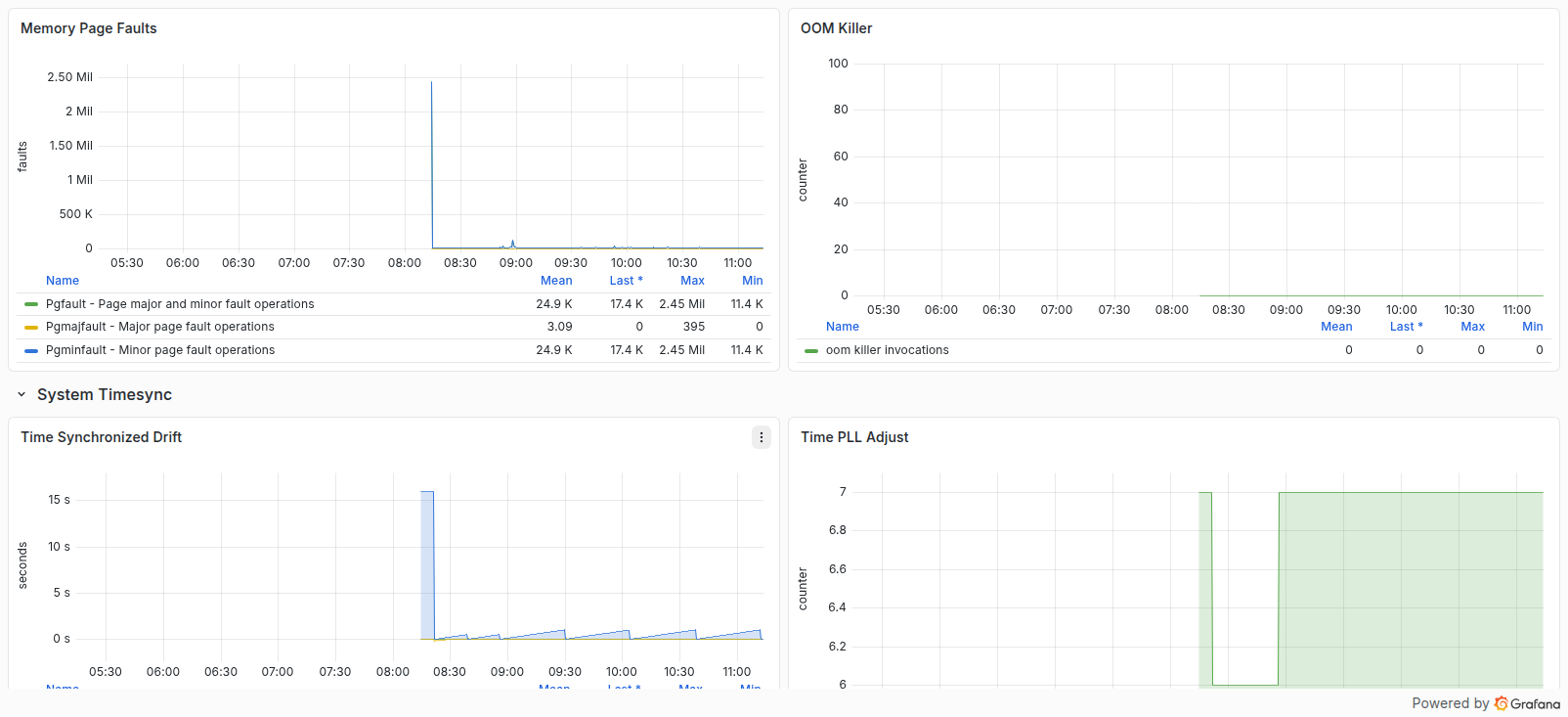
زمان سیستم، فرایندها و سختافزار
System Timesync
پنلهای Drift، Status، PLL Adjust و Time Misc وضعیت همگامسازی ساعت را نشان میدهند. node_timex_sync_status=0 یا Drift بالا میتواند نشانه مشکل NTP یا Chrony باشد.
System Processes
این ردیف وضعیت فرایندها، نرخ Fork، PID، Thread و File Descriptor را نسبت به Limit سیستم نمایش میدهد. فرایندهای blocked، جهش Fork یا نزدیکشدن مصرف به Limit نیازمند بررسی است.
System Misc
پنلهای System Load، Context switch، Interrupt و شاخصهای عمومی Kernel را برای شناسایی فشار یا رفتار غیرعادی سیستم نمایش میدهند.
Hardware Misc
این ردیف فرکانس CPU، دما، Cooling throttle و وضعیت منبع تغذیه را نشان میدهد. کاهش فرکانس هنگام بار بالا، دمای نزدیک حد بحرانی یا آفلاینشدن منبع تغذیه نیازمند بررسی سختافزاری است.
Systemd
پنلهای Systemd Units State و Systemd Sockets وضعیت Unitها و Socketها را نمایش میدهند. Unitهای failed را با systemctl و لاگهای Journald بررسی کنید.
ذخیرهسازی و فایلسیستم
Storage Disk
پنلهای IOPS، داده خواندن و نوشتن، Average wait، Queue size و زمان صرفشده برای I/O وضعیت عملکرد دیسک را نشان میدهند. زمان انتظار و طول صف پایدار همراه با Utilization بالا معمولاً نشانه گلوگاه ذخیرهسازی است.
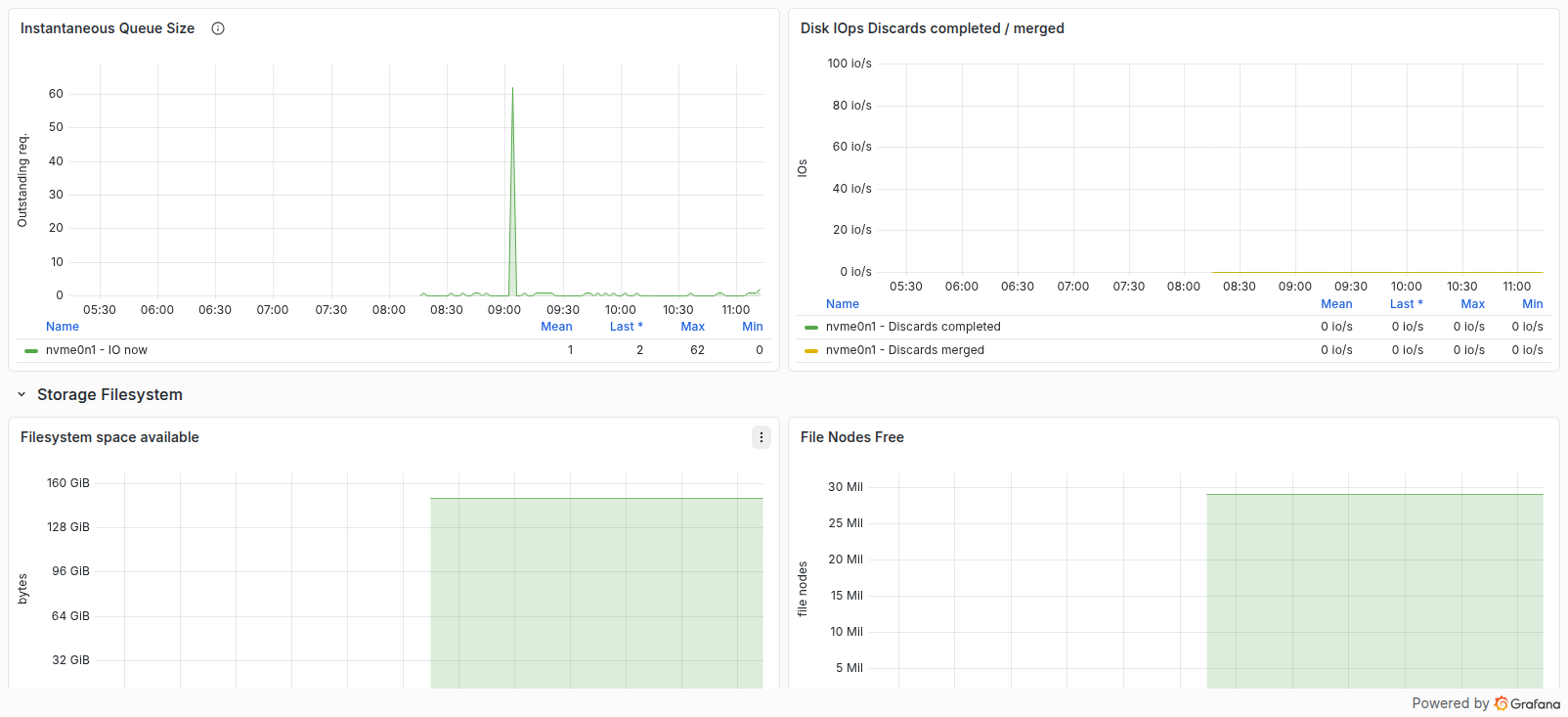
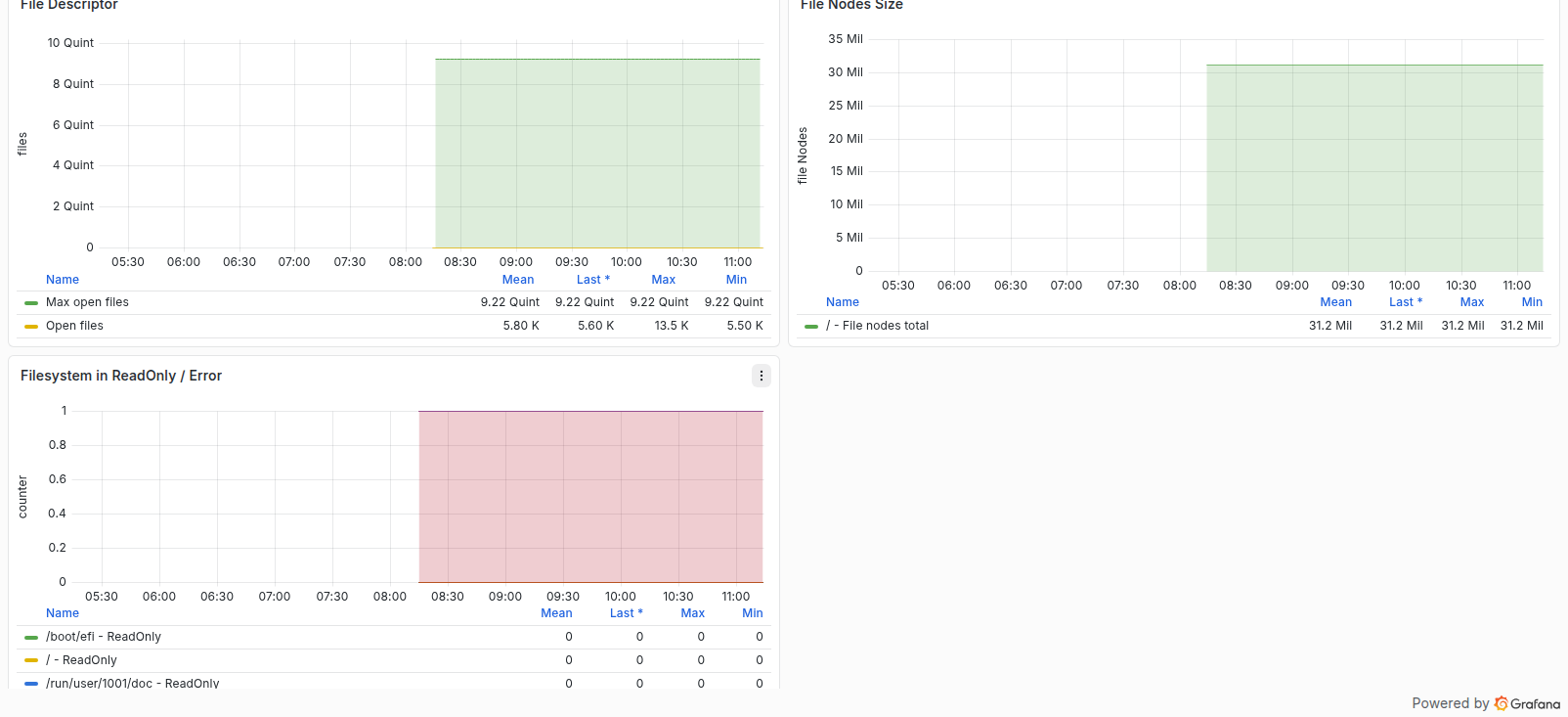
Storage Filesystem
این ردیف فضای آزاد، Inodeها و وضعیت ReadOnly یا Error فایلسیستم را نمایش میدهد. تمامشدن Inode حتی با وجود فضای آزاد مانع ایجاد فایل میشود؛ هر مقدار غیرصفر در Filesystem in ReadOnly / Error را بحرانی در نظر بگیرید.
شبکه
Network Traffic
این ردیف ترافیک رابطها، وضعیت عملیاتی و خطاهای Drop، FIFO، Frame، Carrier و Collision را نشان میدهد. نرخ مطلوب خطاها صفر است؛ مقدار غیرصفر پایدار میتواند به رابط، Driver، کابل، Switch یا ازدحام مسیر مربوط باشد.
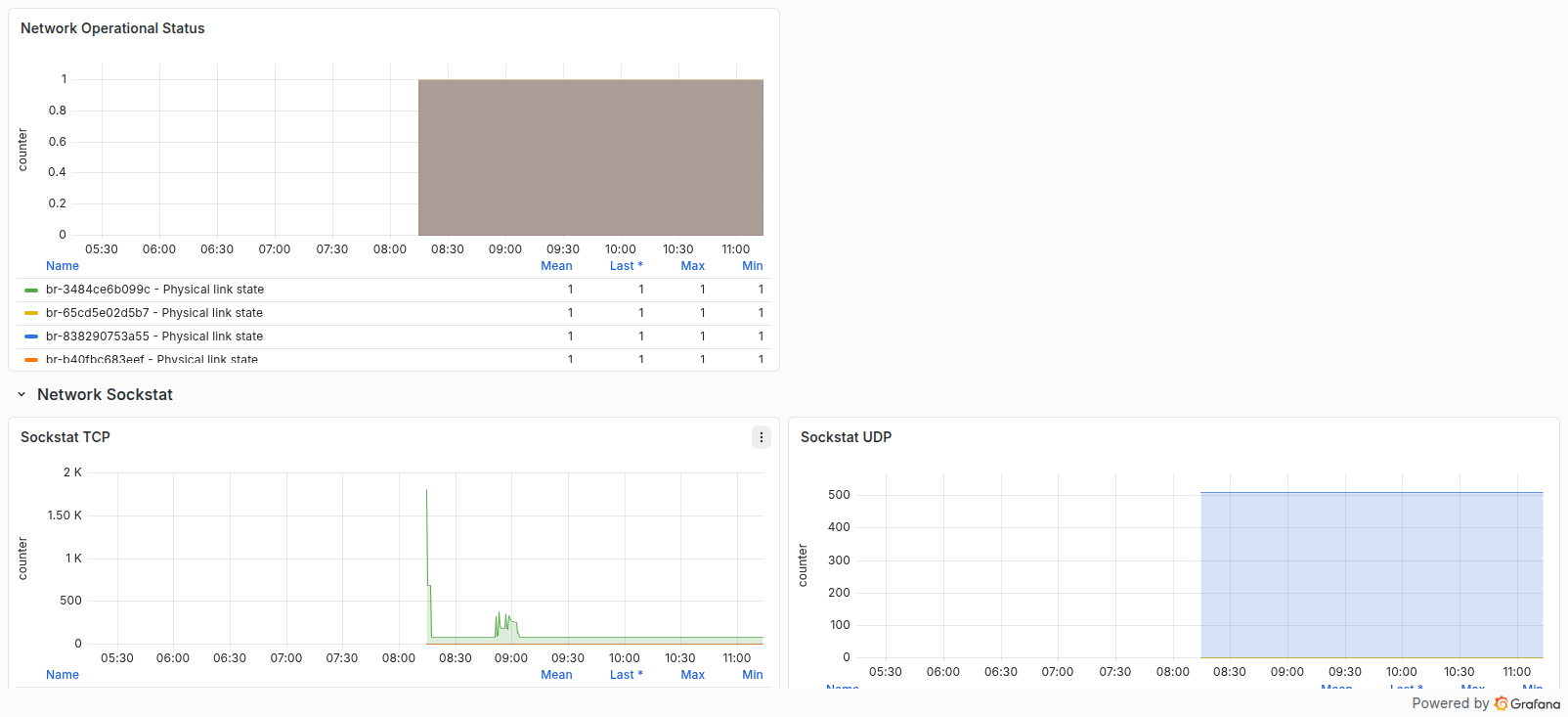
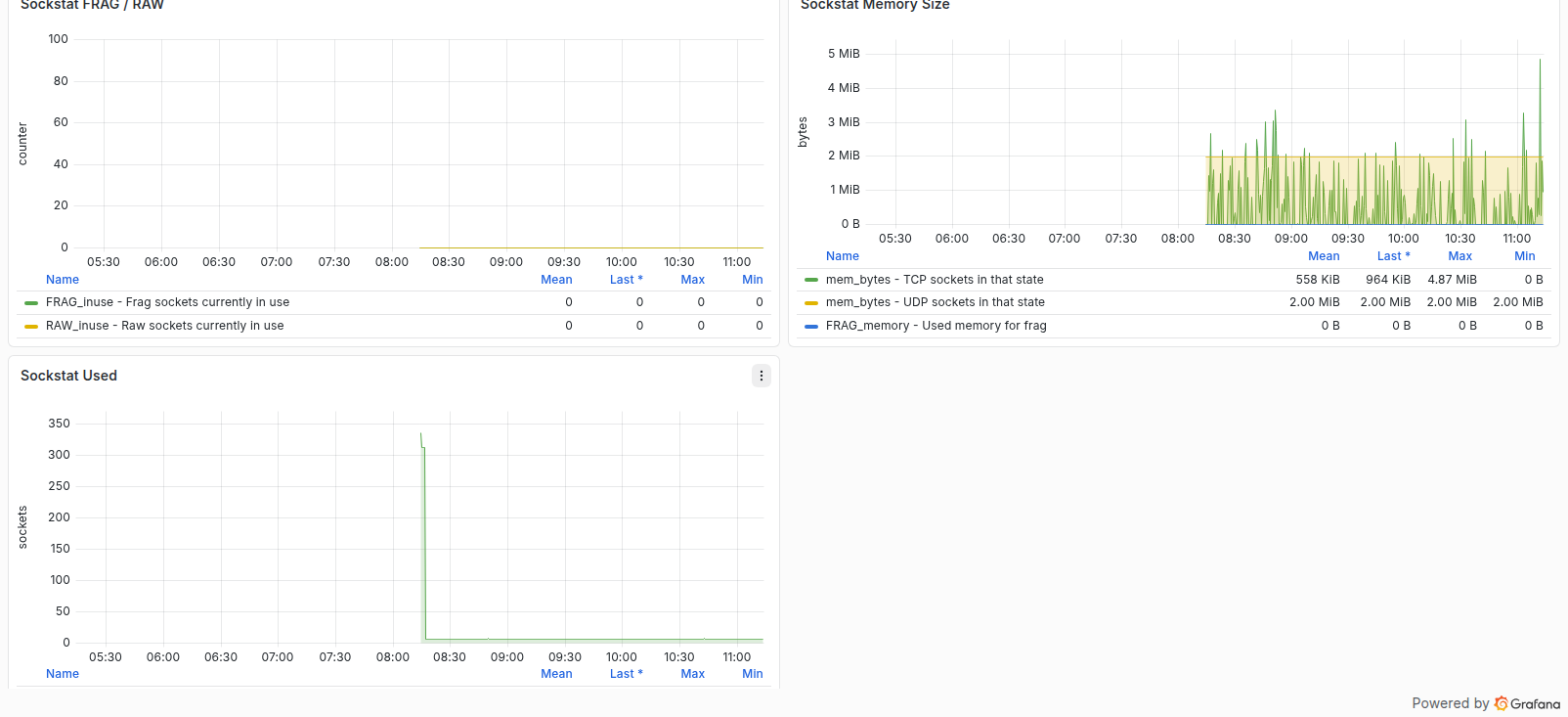
Network Sockstat
پنلهای Sockstat مصرف Socketها و وضعیت حافظه شبکه را نمایش میدهند و برای تشخیص فشار روی Network stack یا رشد غیرعادی تعداد Socketها مناسباند.
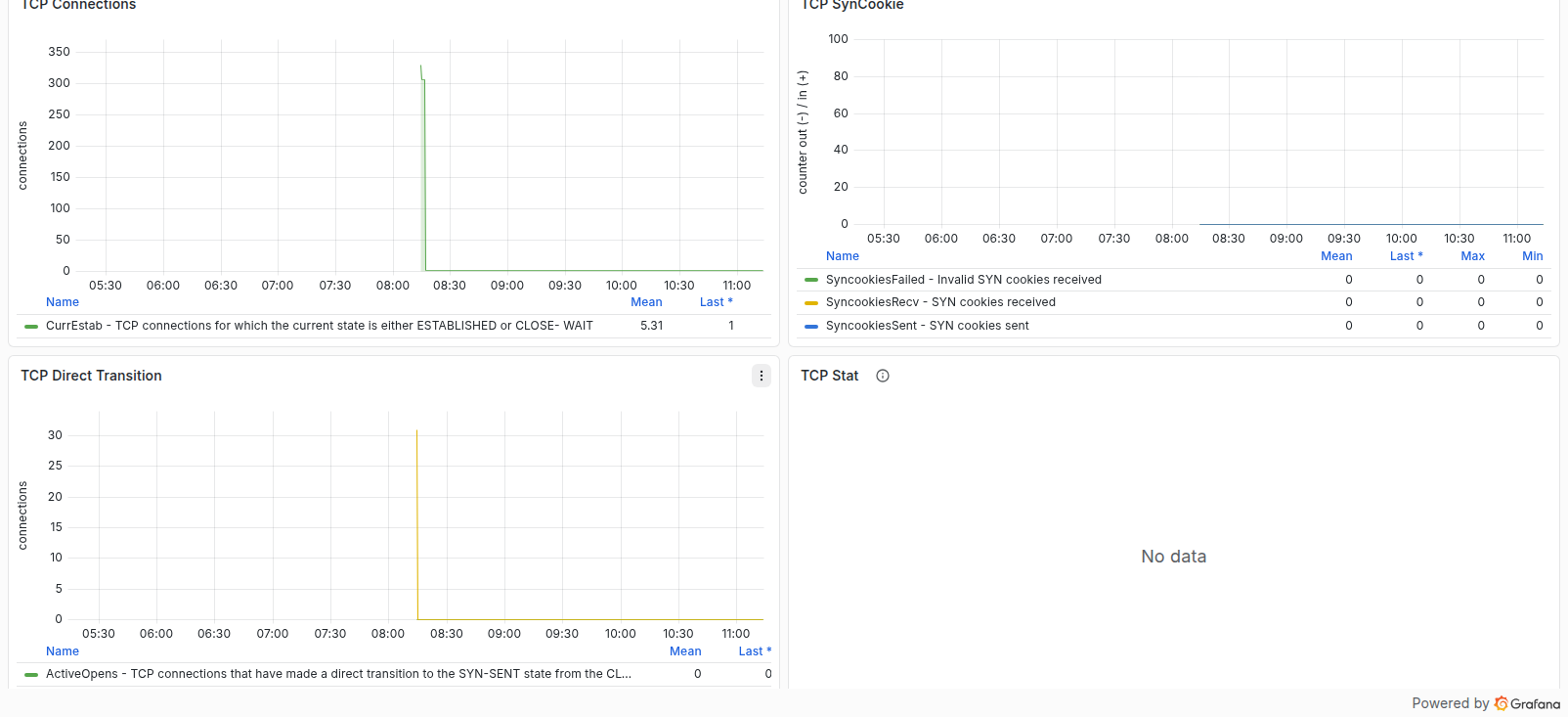
Network Netstat
این ردیف ICMP، UDP و TCP ورودی و خروجی، خطاهای پروتکلی، Connectionها، SynCookie، Conntrack و Softnet را نمایش میدهد. Drop یا Squeezed غیرصفر و نزدیکشدن Conntrack به Limit نیازمند بررسی است.
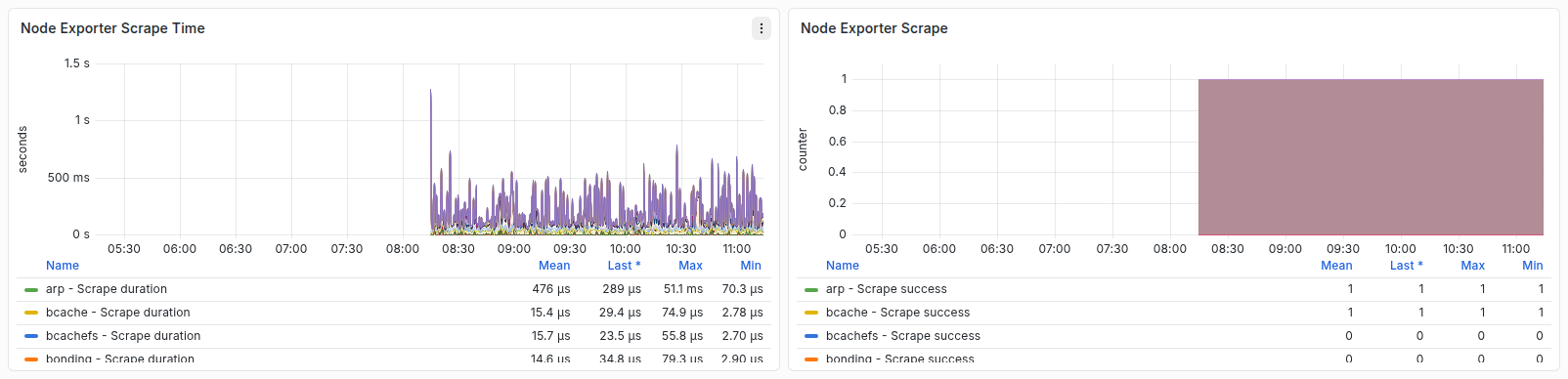
وضعیت جمعآوری متریکها
Node Exporter
پنلهای Node Exporter Scrape Time و Node Exporter Scrape مدتزمان و نتیجه جمعآوری متریکها از Collectorها را نشان میدهند. افزایش Duration یا Scrape ناموفق میتواند ناشی از Collector کند یا ناموفق باشد و لزوماً به معنی اختلال خود سرور نیست.
هشدارهای مرتبط
هشدارهای زیر مستقیماً به پنلهای این داشبورد لینک شدهاند:
| Alert | پنل لینکشده | شرط | Severity |
|---|---|---|---|
NodeStoppedReportingHamdar |
Uptime (id 15) |
اخیرا node_uname_info > ۱۸۰s؛ for: 3m |
critical |
UnexpectedRebootHamdar |
Uptime (id 15) |
تغییر Boot time در ۱۵ دقیقه؛ for: 0s |
warning |
HighCPUHamdar / …Critical |
CPU Busy (id 20) |
CPU > ۸۰٪ / ۹۵٪؛ for: 10m |
warning / critical |
HighMemoryHamdar / …Critical |
RAM Used (id 16) |
RAM > ۸۵٪ / ۹۵٪؛ for: 10m |
warning / critical |
HighLoadHamdar / …Critical |
Sys Load (id 155) |
Load > ۱۵۰٪ / ۳۰۰٪؛ for: 15m |
warning / critical |
DiskSpaceLowHamdar / …Critical |
Root FS Used (id 154) |
/ > ۸۵٪ / ۹۵٪؛ for: 15m |
warning / critical |
DiskWillFillSoonHamdar |
Root FS Used (id 154) |
پیشبینی پرشدن ظرف ۷ روز؛ for: 30m |
warning |
SwapHighHamdar |
SWAP Used (id 21) |
Swap > ۵۰٪؛ for: 15m |
warning |
پس از فعالشدن هر Alert، از لینک پنل برای بازکردن همین داشبورد در بازه زمانی رخداد استفاده کنید. شرح هشدار و اقدامات پیشنهادی برای هر مورد در بخش هشدارها آمده است.
پیوست فنی
این بخش برای نگهداری و Provisioning داشبورد است و در بررسیهای روزمره کاربردی ندارد.
| ویژگی | مقدار |
|---|---|
| پوشه Provisioning | hamdar (dashboards/hamdar/hamdar-server-metrics.json) |
| UID | fectkhd6s3ny8e |
| Datasource | VictoriaMetrics (monitoring-prometheus) |
| فیلتر محصول | product="hamdar" |
| شناسه Node | instance و job |
Queryهای کلیدی داشبورد:
| هدف | Query نمونه |
|---|---|
| بالا بودن Node | اخیرا node_uname_info{product="hamdar"} (سری up استاندارد وجود ندارد) |
| Uptime | node_time_seconds{product="hamdar"} - node_boot_time_seconds{product="hamdar"} |
| CPU Busy | 100 * (1 - avg(rate(node_cpu_seconds_total{product="hamdar",mode="idle"}[$__rate_interval]))) |
| Load نرمالشده | node_load1{product="hamdar"} * 100 / count(count(node_cpu_seconds_total{product="hamdar"}) by (cpu)) |
| RAM Used % | (1 - node_memory_MemAvailable_bytes{product="hamdar"} / node_memory_MemTotal_bytes{product="hamdar"}) * 100 |
| Root FS Used % | 100 - node_filesystem_avail_bytes{product="hamdar",mountpoint="/"}*100 / node_filesystem_size_bytes{product="hamdar",mountpoint="/"} |
| Swap Used % | بر پایه node_memory_SwapTotal_bytes{product="hamdar"} و node_memory_SwapFree_bytes{product="hamdar"} |
| OOM | irate(node_vmstat_oom_kill{product="hamdar"}[$__rate_interval]) |